My daughter turns three in June. Yesterday, we were playing and an idea popped into my mind: she likes to help me build various electronic things at my desk, but she’s never really built anything of her own. I asked if she wanted to make something with me and she energetically agreed.
Here it is:
It’s a simple two-transistor astable multivibrator that alternates between the red and green LEDs at around 2Hz. Everything to the right of the red wire is pretty bog-standard: 5% tolerance 470 ohm current-limiting resistors for the LEDs and 100k ohm resistors for charging the 10uF capacitors. Two BC548 transistors do the switching. Some 24 AWG wire connects parts too far apart (or awkwardly placed) for component leads to reach.
In retrospect, I could have laid things out better, but she didn’t mind. The only major thing I’d change is using ceramic capacitors instead of electrolytic, as I’d like to keep this circuit around until she’s older and have it still work without the capacitors drying out, but I didn’t have any 10uF ceramics at hand. I’ll order some, have her pick them out, and swap them out.
On the left is a simple terminal block for connecting a power supply. I wanted the circuit to be robust in terms of polarity, so I used a bridge rectifier so it can operate regardless of how the DC power supply is connected (I could have added a filter cap so AC could be used too, but I don’t have any wall warts with AC out, and she likes batteries, so this was not a major design consideration). I could have used a cheap diode, but the bridge rectifier uses Schottky diodes and so drops only 0.6V compared to a 1N400x’s 0.7V, plus it means the circuit will work (rather than simply not be destroyed) regardless of how it’s connected, so that was an easy and robust choice.
A 50mA polyfuse provides protection from faults (important when using old cellphone Li-Ion batteries as a power source). All the exposed underside contacts of the unfused section (i.e. terminal blocks and rectifier) are liberally coated with hot glue for insulation, with the jumper wires on the top and bottom tacked down with hot glue as well. All solder and components are lead-free, with burrs and other sharp points on connections filed smooth for minimal danger.
My daughter loved picking the components out of the parts drawers, listened attentively while I explained what they did and how they work, and helped me put them in the correct places on the breadboard. After things worked and she (later) went to bed, I moved the same parts over to a protoboard for a bit more durability. Now she’s running around the house waving it (and the 1000mAh cellphone battery stuck to the bottom with double-sided tape) around, blinking it at her baby brother, and integrated it into playing with her other toys.
I recently acquired a FLIR ONE thermal camera, which deserves a separate post reviewing it, but for now let’s look at the TP4056 Li-Ion charger with integrated protection circuitry.
This is a pretty bog-standard, dirt-cheap Li-Ion charger that works really well. It does what it says on the tin: CC/CV charging, with charging current adjustable by replacing a specific resistor, 5V MicroUSB input, and pads/holes to accept connections to the cell, the load, and the charging power source (if one doesn’t want to use the USB port). No complaints at all, and no surprises.I like that it has a battery protection circuit as well: the protection chip monitors the charging or discharging current and voltage, and protects the cell against overvoltage (e.g. from over-charging), undervoltage (e.g. from over-discharging), and over-current situations by switching off the MOSFET that connects the battery to the load and charging chip.The FET is arranged in a cool way such that, even if the over-discharge protection has tripped and the FET is open, you can trickle charge through the FET’s body diode at a very low rate in order to slowly charge the cell up without stressing it. Once it reaches the release voltage, the cell will charge at the normal speed.One of the main reasons I bought the FLIR ONE thermal camera is to observe various electronic devices I have and see how hot they get, where the heat is dissipated, etc. Since the TP4056 is a linear charger and produces a modest amount of heat while charging, I figured this would make a great first test. Here’s one of the images I snapped:
As you can see, the chip gets moderately toasty when charging at 1A, and I can’t hold my finger on it for a more than a second or two. This is a top view with the chip and other components visible to the camera. The TP4056 also has a thermal “radiator” (using the language in the datasheet) pad on the bottom that should be connected to a copper plane on the PCB. The board has a bunch of thermal vias under the chip to conduct the heat away to the other side and the backside of the board is about the same temperature as the front. Neat.
I foresee a lot of fun (and useful projects) with both the camera and the battery charger.
I ran into some trouble today getting an HC-05 bluetooth-to-serial module to communicate with my Trimble Resolution T GPS receiver.
The ResT will send some data automatically once per second, but needs to be polled to send other data. Lacking the polling packet, weird things happen.
Some devices have built-in pull-up resistors so the module works fine, but the ResT doesn’t. The HC-05’s TX pin is open-drain, so without a pull-up it does nothing, causing confusion. Putting a >1k pull-up to 3.3v on that pin works wonders.
This is the first of (hopefully) several “notes to self”. They are intended as a record of my various tinkerings and processes that I’ve learned. Although publicly readable, they’re meant as notes to myself in the context of my personal setup and are not really intended as complete “how-to” guides. If you find it useful, awesome! If not, sorry.
The version of NTPd packaged in Raspbian Jessie doesn’t have support for PPS (why?!) or the Motorola Oncore driver enabled. It needs to be recompiled to support those options. The Oncore hardware is quite old, so I understand them not wasting a bit of space by enabling the Oncore driver at compile-time (though really, disk space is cheap and abundant), but no PPS? C’mon. Continue reading “Note to Self: Raspberry Pi & Motorola Oncore UT+ setup”
I’m pretty sure that it’s some sort of universal law that all Certificate Authority websites must be filled with obfuscating marketing-ese wording, links to “white papers”, contradictory and uninformative text, and content generally tailored for manager-types.
Honestly, I don’t know why they do this: TLS certificates are essentially always handled by technical staff — not management — at companies. Smaller organizations typically leave the administration of TLS certs to their commercial web hosts (again, technical staff). Individual site operators either know how to handle certs or don’t, but for those who don’t the marketing fluff on a CA website isn’t likely to help at all.
There may be some very specific reason why a particular CA is required, such as needing to support particular software or devices that only include a limited selection of roots, and while these reasons may be decided by managers and executives, the actual deployment is done by technical staff. The CA websites should really be tailored for technical people, not managers.
In addition to the typical manager-speak found on CA websites, the amount of confusing information is shocking. Some of it is merely misleading (e.g. implying that a particular certificate enables 128/256-bit symmetric ciphers rather than merely vouching for the identity of the server; the supported symmetric ciphers are set in the server configuration independently of the certificate and are negotiated with the client), while others are outright deceptive: Symantec/Thawte go so far as to claim that Server-Gated Cryptography is still relevant in this day and age (hint: it isn’t). In addition to being absurdly insecure and out of date, 16+ year old “export-grade” browsers that require SGC for strong cryptography are likely completely incapable of rendering modern websites in a comprehensible manner. Supporting such ancient browsers is a Bad Thing.
I’m also surprised at how hideous some of the CA websites appear: quite a few look like they haven’t been updated in at least a decade.
Lastly, there’s just way too many options presented by CAs. Domain-validated certificates are cheap and easy, though there’s no reason why phishing websites and the like can’t get perfectly-valid DV certs for their misleading or fraudulent sites: they do, after all, legitimately control their domain.
Still, DV certs provide reasonable protection from man-in-the-middle attacks, and CAs like Let’s Encrypt make DV certs available for free in an easily automated and installed way. If Let’s Encrypt’s ACME validation system won’t work for certain purposes, commercial CAs like Comodo and GeoTrust offer incredibly cheap DV certs in the form of PositiveSSL ($5/year) and RapidSSL ($9/year), respectively. Even Thawte offers relatively cheap “SSL123” DV certs for $31/year. There’s really no excuse for not using HTTPS.
Extended validation certs are useful for major companies, banks, etc. as the CA actually verifies the legitimacy of the entity behind the domain name. It should be extremely unlikely for any EV certificate to be issued illegitimately, though users might not actually check for anything more than the “green bar” (if they do that at all), so I generally think EV certs are a good idea.
That said, I’m not sure why there’s such an extreme price difference for EV certs. For example, compare Comodo ($101/year) and GeoTrust ($125/year) with Symantec ($600/year to $900/year) — the roots are equally ubiquitous and trusted, perform the same validation, and users never bother to check which CA actually issued a cert. So long as the green bar appears and the browser doesn’t yell at them, they don’t care.
Organizational and individually-validated certs are essentially worthless. They appear the same as DV certs in browser interfaces (no green bar), and essentially nobody bothers to check the O and OU fields in a certificate.
Charging more for wildcards is annoying, as it doesn’t cost the CA anything extra to issue; one of the reasons I liked StartSSL (before their WoSign-related drama) was that they only charged for things that required human action. Domain-validated certificates for non-commercial purposes are completely free of charge. OV and IV certs require a human to perform the validation, and customers pay an annual fee to be validated. Once validated, customers could issue an unlimited number of certificates — including wildcards — for any domains they controlled. EV certs were a bit different, but still quite cheap. That was a refreshing change from the business-as-usual of the CA industry, though StartSSL seem to have screwed themselves over with shady behavior after being acquired by WoSign.
Simply put, CA websites and their offerings suck. They’ve always sucked, currently suck, and likely will always suck in the future. I have no idea why such wildly-profitable organizations can’t design a website that doesn’t suck and is targeted to the relevant technical people.
Edit: It’s been brought to my attention that SSLs.com no longer offers GeoTrust, Thawte, Symantec certificates, and instead only offer Comodo certificates. I’ll keep the links here for historical purposes, but if you want to get such certificates you’ll need to find another vendor.
Last year, StartSSL, a popular Israeli certificate authority of which I myself have been a customer, was quietly purchased by WoSign, a CA in China. All well and good, such things happen fairly often in the industry.
However, they cut some corners: WoSign didn’t disclose the purchase to Mozilla, in violation of Mozilla’s policy. On its own, that’s not a super-critical issue, but that’s not all they did: based on information provided in a Mozilla report, WoSign has been caught backdating SHA1-signed certificates to avoid an industry-wide ban on that hash algorithm due to its cryptographic weakness, going so far as to provide a standardized internal framework for issuing backdated certificates. Additionally, they used the newly-acquired StartSSL to issue at least one backdated certificate.
Evidently they did this because Windows XP SP2 (a long-outdated version of XP, which is itself in end-of-life status) is quite popular in China and does not support SHA256 signatures, so there is a demand for SHA1-signed certificates. In addition, some payment processors in the US didn’t plan ahead and found some of their old payment terminals only supported SHA1 and were unprepared for the deadline and so got WoSign to backdate some new certificates to avoid any issues.
In addition, WoSign’s back-end software used for validating domains, issuing certificates, etc. has evidently had a series of bugs that have resulted in them improperly issuing certificates for GitHub and the University of Central Florida without the approval of either organization. A bug also allowed an attacker to bypass domain validation entirely and have WoSign issue certificates for unvalidated domains. While bugs are an unavoidable part of software development, such critical bugs should have been found very early in testing and never made it to production.
Their internal policies seemed geared toward “issue first, validate later and revoke if necessary”, which is absolutely the wrong way to issue certificates and which is in violation of the CA/Browser Forum Baseline Requirements.
Shockingly, WoSign’s auditor, Ernst & Young (Hong Kong), didn’t catch any of these glaring issues.
Needless to say, Mozilla isn’t happy and is discussing what to do. Right now, the most likely response is to untrust new WoSign and StartSSL-issued certificates for a period of at least one year, after which time they could reapply for trusted status by undergoing both the standard audits as well as some extra, Mozilla-specified scrutiny. Existing certificates from the CAs would continue to be recognized, but no new trusted certificates could be issued by those companies.
I find the solution to be quite elegant: CAs have occasionally played a bit fast and loose, and have relied upon their “too big to fail” status. Revoking the trust bits outright for a major CA like Symantec/VeriSign, Comodo, or even relatively smaller ones like StartSSL and WoSign, would cause a massive disruption for innocent customers of that CA and was generally only considered for the most extreme cases (see DigiNotar).
Instead, the solution proposed by Mozilla allows innocent customers to continue to use their certificates without disruption until they come time for renewal, at which point they’ll need to find some other option. The CA, however, is penalized by being unable to issue new certificates (if they do issue new certificates they’ll be untrusted, and Mozilla has threatened to blacklist the entire CA immediately if the backdates certs to avoid the restriction) and thus loses both reputation and business.
I suspect that Google, Microsoft, and Apple will follow Mozilla’s lead, so the penalty will be essentially universal.
Personally, I’m saddened by the whole situation: other than a somewhat-clunky web interface, StartSSL had been a solid CA for years prior to their acquisition. The one black mark was their response to Heartbleed (they were charging for revoking compromised certificates) which, although in accordance with their policies, was a bit of a dick move and bad PR. I used StartSSL certs on many of my sites and had recommended them to others.
After the acquisition by WoSign (which had not been pointed out for nearly a year), StartSSL’s website switched to a poorly-translated version made in their China office (according to StartSSL). Although the speed of certificate issuance improved, the overall change was negative, with the web interface being laughably bad to use. The quality of customer service also decreased.
Still, StartSSL brought it on themselves. I no longer use StartSSL certs and don’t recommend anyone use them going forward. I may change my mind at some point in the future once they prove they’re trustworthy again, but not now.
Currently, I recommend using Let’s Encrypt, an open, automated and free CA — this site uses LE-issued certs. Installation and server configuration is automatic and easy, and renewals are handled automatically by cron job. It couldn’t be easier and I’m extremely happy.
For certain other, internal services I maintain that don’t play nice with Let’s Encrypt, I like Comodo PositiveSSL certificates sold by the reseller SSLs.com. Certs are cheap (around $5/year), issued in minutes, with a validity period up to 3 years. Unlimited reissues are included. Customer service is responsive and clueful. The one downside is their self-service interface only supports RSA certificates; if you want to use ECC certificates (Comodo PositiveSSL offers both all-RSA and all-ECC chains, which is nice) you’ll need to send the CSR to their customer service staff, who will manually submit it to the CA. They usually do this quite quickly.
A while back I needed to interface a GPS timing receiver that only has an RS-232 serial connection with one of my Raspberry Pis. The Pi only supports TTL-level serial and only tolerates voltages between 0-3.3V its the UART pins.
Enter the MAX3232, a chip from Maxim Integrated that converts between RS-232 and TTL serial with supply voltages from 3.0 to 5.5V. It produces “true” RS-232-level voltages (both positive and negative) using built-in charge pumps and some small external capacitors. Just the ticket for what I needed.
Alas, the MAX3232 isn’t really something one can run down to the local electronics shop (and there isn’t any such shop where I live in Switzerland, as far as I know) and pick up. Typically it’s purchased by manufacturers in quantity from major suppliers. Hobbyists like myself need to turn to the internet where such things are available in abundance for cheap from China, though one must be wary of counterfeits. Of course, I could order from legitimate Swiss distributors, but small-quantity pricing and shipping are extremely high (>$10 USD per chip!) compared to major US distributors like DigiKey and Mouser.
In my case, I ended up buying a few boards like this one from an online vendor in China. The listing specifically states it had a MAX3232 chip. My thought was that if it was a legitimate chip, cool. If not, it’d be an interesting experiment and I’d get some cheap DE-9 connectors out of the deal.
Fake “MAX3232” Board
To the naked eye, everything seemed to be reasonable. The chip did have markings identifying it as a MAX3232 (falsely, as I later discovered; read on!). The board worked and the chip functioned within the specs in the Maxim datasheet and it even broke out the chip’s second RS-232-to-TTL channel on the header pins.
However, the first board failed after a few weeks, drew significant current, and dramatically overheated. By “overheated” I mean “blister-raising burn on my fingertip”-level-hot. Also, the data-transfer LEDs were glowing faintly all the time rather than flickering on and off when data was flowing.
Figuring this was just some bad luck on my part (this is before I got the anti-static mat on my desk), I swapped it out for another board. I was particularly careful with anti-static precautions, and put the board over a small glass container just in case it overheated and caught fire. Although it didn’t catch fire (thankfully!), it did fail after a few weeks and overheated just like the first one.
Ok, so something’s going on, but what? Since the chips had obviously failed, I figured I couldn’t harm them with some ham-fisted SMD desoldering, so I took them off their respective boards.
Here’s the results of my handiwork, as viewed under a petrographic microscope in the lab (I used a handheld camera aimed through the microscope eyepiece for all the microscope photos, hence the weird vignetting at the edges):
Fake MAX3232 #1 PackageFake MAX3232 #2 Package
All right, quit laughing! De-soldering SOIC chips using a handheld soldering iron is no fun.
Anyway, the markings are inconsistent and seem pretty low-quality. Definitely not something I’d expect from Maxim. For comparison, I had ordered a free MAX3232 sample directly from Maxim (thanks, guys!) and it arrived a few days later. Here’s the legit chip:
Genuine MAX3232 Package
According to the date code, I ended up killing this chip in the name of science about 2-4 weeks after it was made. Sorry, little guy. Anyway, you can see the markings of the real chip are distinctly different from the fake chips. The differences are striking even with a handheld magnifying glass: the real chip has distinct laser-etched markings with a textured surface. The fake chips have much “weaker” etching with a much flatter, duller surface.
Next, I decapsulated all three chips (two fake and one genuine) by dissolving them in hot nitric acid followed by an acetone wash and a few minutes in the ultrasonic cleaner. Don’t try this at home (or at least not in my home!): I did it in a controlled environment with a fume hood, proper ventilation, protective gear, etc. Zeptobars and the CCC have some interesting guides on how to do this if you’re interested. Be careful.
Alas, I wasn’t able to do the preferred method of just dissolving the package over the silicon die itself. Instead, I decided to dissolve the entire chip package, legs and all. Interestingly, the genuine one dissolved much more rapidly (but at a consistent rate) than the fakes; the fakes resisted the acid for nearly an hour, then quickly dissolved in a few minutes. The package seemed to be the same blackish epoxy that most chips are encased in, so I have no idea why they would behave so differently in acid. Any materials-type people have any ideas?
Here’s what the real MAX3232 die looks like:
Genuine MAX3232 Die
Note the gold bond wires are still attached and didn’t dissolve in the acid bath. I’m not a semiconductor expert, so I can’t tell you what the actual regions of the chip actually are, but it’s a pretty picture and serves as a good reference for comparing the others. Also, the genuine die is about 50% longer than the fakes so it couldn’t fit entirely in the field of view of the microscope.
Here’s a closeup of the “Maxim” marking on the genuine chip as well as a date code. Presumably it refers to when the chip design was finalized.
Maxim Mark on Genuine MAX3232
Now, let’s look at the fakes. Both fakes were, unsurprisingly, identical.
Without magnification, the dies are pretty small and it’s hard to make out any detail.
The fake MAX3232 die is quite small. The real one is only a millimeter or so longer.
Under the microscope, we can see the die quite well.
Fake MAX3232 Die
The above photo was taken at the same magnification as the genuine MAX3232 die photo: you can see the fake die is much smaller, has a much different appearance, and didn’t use gold bond wires. Whatever metal was used for the wire dissolved away in the acid.
Both chips had the same markings: they appear to have been designed in November 2009, and the marking on the second line appears to be “WWW01” (though I’m not sure if it’s the number zero or the letter “O”). I’ve had no luck figuring out what that means.
As I mentioned above, I’m not an expert on low-level chip design or failure analysis and I was unable to find any obvious-to-the-layman failure in the chips that would have resulted in them passing significant current and overheating. Any ideas?
Thermocouples are amazing temperature sensors. They’re simple (just two wires!), cover a wide range of temperatures, have no moving parts, are incredibly robust, and are easy to use and deploy.
However, the temperature-dependent voltage they produce is very small (for example, the common K-type I refer to throughout this post produces a nominal 41.276μV/°C) and they require temperature compensation if their “cold junction” (the end not being used to measure something and which is not necessarily colder than the sensing end) is not at exactly 0°C, so purpose-built chips like the MAX31855 are made to amplify the very weak signal, measure the cold junction temperature and apply the necessary compensation, digitize the readings, and provide the result over a digital interface like SPI.
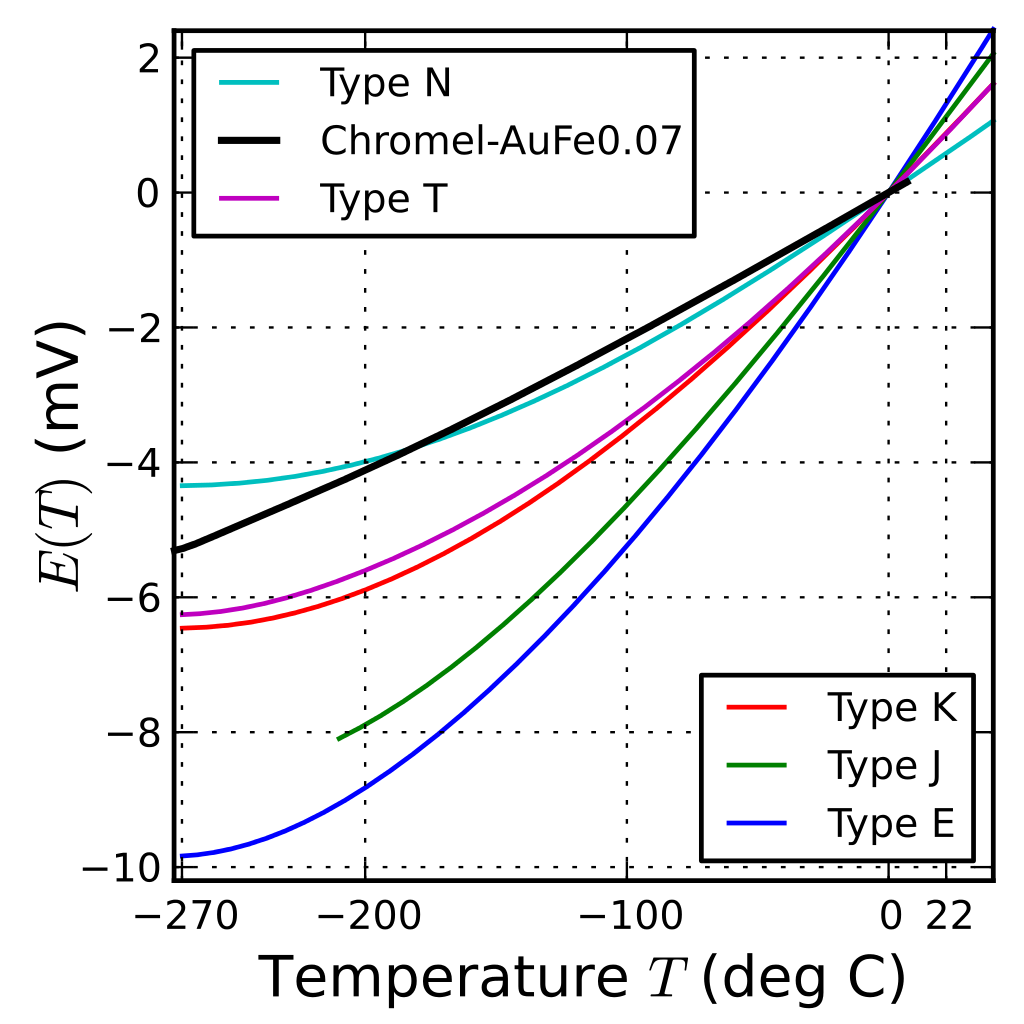
However, the MAX31855 has one glaring issue: it assumes the temperature-to-voltage relationship (the “characteristic function”) of the thermocouple is linear over its entire -200°C to +1,350°C temperature range. It isn’t.
In fact, for K-type thermocouples, the characteristic function goes highly non-linear at very low temperatures. Ideally, E(-100°C) would be -4.128mV. Instead, it’s -3.554mV according to the NIST tables. E(-200°C) should ideally be -8.256mV, but it’s actually -5.891mV. Yikes!
Characteristic function for selected thermocouple types at low temperatures.
At positive temperatures, K-type thermocouples are significantly more linear, with <1% error at 1,000°C and ~2.2% at 1,350°C. Although the MAX31855 works across the full range of temperatures for K-type thermocouples, it’s obviously designed to be mainly used in the linear, positive-temperature territory.
Part of my work involves measuring things at both liquid nitrogen temperatures (-195°C) and at very high temperatures (200-1,000°C). I can tolerate an error of a few degrees, but when I immersed a type-K thermocouple in liquid nitrogen and connected it to a MAX31855, the reported temperature was only -130°C.
Not good.
Fortunately, the good folks at Maxim Integrated provided me with a handy guide on how to properly correct the non-linearized output of the MAX31855. It’d be easy if the chip would provide us the actual thermocouple voltage it measured, but it doesn’t (darn!), so we need to reverse to calculations it does internally to derive the measured voltage so we can apply the corrections.
Let’s walk through how to do so in 5 easy steps. We’ll use the example values from the guide: the true temperature being measured is -99.16°C, the cold junction temperature is 22.9375°C, and the non-linearized cold junction-compensated temperature (“raw”, using the guide’s term) output by the MAX31855 is -84.75°C.
First, subtract the cold junction temperature from the raw temperature:-84.75°C – 22.9375°C = -107.6875°C
Next, calculate the thermocouple voltage corresponding to that temperature if we assume the thermocouple was perfectly linear and E(T) was 0.041276mV/°C:-107.6875°C * 0.041276mV/°C = -4.44490925mV
This part’s a bit tricky: we need to calculate the equivalent thermocouple voltage (“E”, in mV) of the cold junction using the cold junction temperature reading from the MAX31855, the NIST temperature-to-voltage coefficients (c0, c1, …, cn and a0, a1, and a2). The an values are only used for positive temperatures. For some reason, Maxim uses different letters for the coefficients than NIST, so keep that in mind. Here’s the formulas we need:For temperatures <0°C:$latex E = \sum\limits_{i=0}^10 c_i \cdot t^i$For temperatures >0°C:$latex E = \sum\limits_{i=0}^9 c_i \cdot t^i + a_0 \cdot e^{\left(a_1 \left(t – a_2\right)\right)^2}$
Where t is the temperature of the cold junction. The coefficients are different for positive and negative temperatures, so be sure you’re using the right values from the table.
The example in the guide has the cold junction near room temperature, so we need to use the equation for positive temperatures. I’m rounding the coefficients here for readability, but you should use the full ones in your code.
The next step is easy: just add the cold junction equivalent thermocouple voltage you calculated in step 3 to the thermocouple voltage calculated in step 2:-4.44490925mV + 0.916753mV = -3.528157mV
The result of step 4 is the linearized thermocouple voltage. Now we just need to convert that voltage to a temperature. Fortunately, NIST has done the hard work for us and provided us with an easy equation:$latex T = d_0 + d_1 \cdot E + d_2 \cdot E^2 + d_3 \cdot E^3 + … + d_n \cdot E^n$, where T is the corrected, linearized temperature in °C, dn are the inverse coefficients given at the bottom of NIST tables (note: there’s three groups of inverse coefficients, each corresponding to a different temperature and voltage range — be sure to use the right one!), and E is the sum of the two thermocouple voltages you calculated in step 4.$latex 0 + \left(2.52 \times 10^{1} \cdot -3.528157\right) + \left(-1.17 \times 10^{2} \cdot -3.528157^2\right) + \left(-1.08 \times 10^{3} \cdot -3.528157^3\right) + … + \left(-5.19 \times 10^{8} \cdot -3.528157^8\right) = -99.16^{\circ}\textrm{C}$
That’s it!
I’ve put up some MIT-licensed example Arduino code at my GitHub repository that will perform the necessary corrections. It uses the Adafruit MAX31855 library to talk to the chip, though it should be easy enough to adapt if you’re not using that library or are developing for another platform. Any suggestions or improvements are welcome!
Fellow Adafruit forum member jh421797 has also made some handy code for accomplishing the same result. It, as well as an earlier version of my code (my GitHub repo has the latest version), is available on the Adafruit site.
Fortunately, Maxim has now released a worthy successor to this chip: the MAX31856 improves on the MAX31855 by adding 50/60Hz line frequency filtering to remove noise induced by power lines, a 19-bit (vs 14-bit for the MAX31855) analog-to-digital converter, support for many different types of thermocouples using a single chip (vs needing to buy a different chip for different types), and, critically, automatic linearization using an internal lookup table.
Interfacing with the MAX31856 is slightly different than the MAX31855, but Peter Easton has released an excellent Arduino library for it. He also makes and sells excellent, US-made breakout boards for the MAX31856 in both 5V and 3.3V editions. I highly recommend them. (Full disclosure: he sold me a few at a discounted rate for testing and evaluation. See my brief review here.)